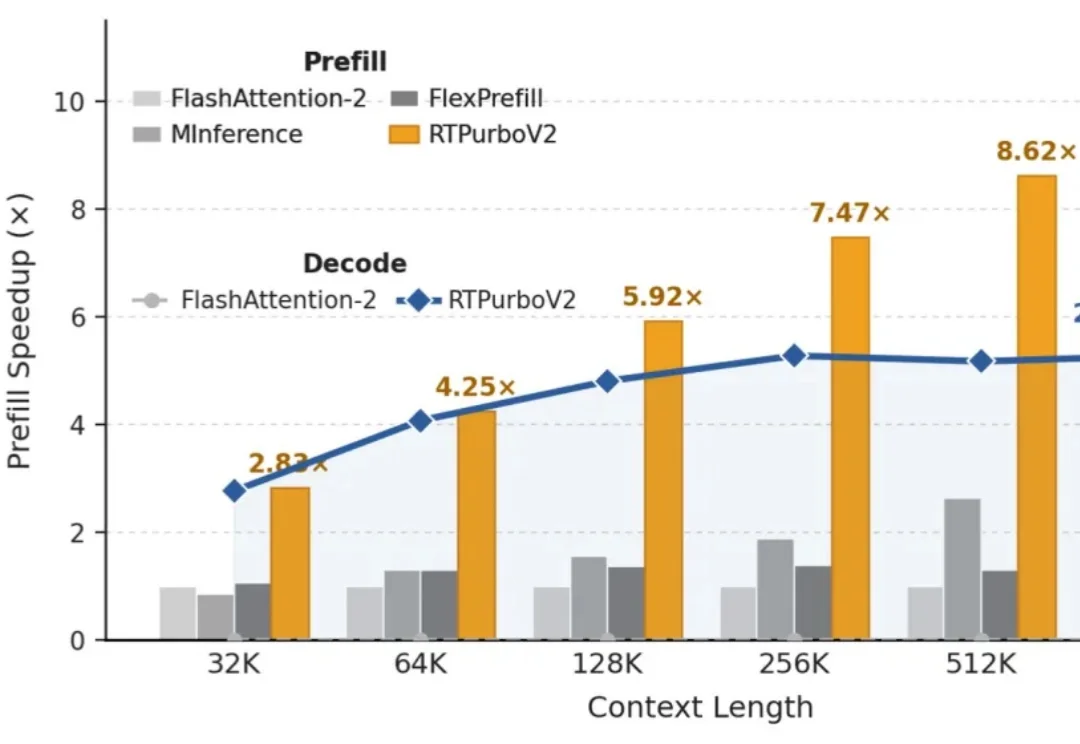
阿里RTPurboV2:原生Transformer再次崛起,百步训练实现10倍稀疏注意
阿里RTPurboV2:原生Transformer再次崛起,百步训练实现10倍稀疏注意“Full Attention 正在被遗忘”
来自主题: AI技术研报
7939 点击 2026-06-08 15:08
 搜索
搜索
“Full Attention 正在被遗忘”

我在 2025 年年度总结的文章《Attention is all you need》里,提到在关注 AI 时代的投资机会,看了很多硅谷的播客和视频,一直想来硅谷看看,但自己认识的这边的人不多,恰好看到Linkloud 组织“创业加速营”,安排了不少硅谷当地的华人创业者、大厂从业人员的交流,就报名了,同去的其他人,还有想要 AI 转型或者就在 AI 领域创业的创始人或者中高管等。
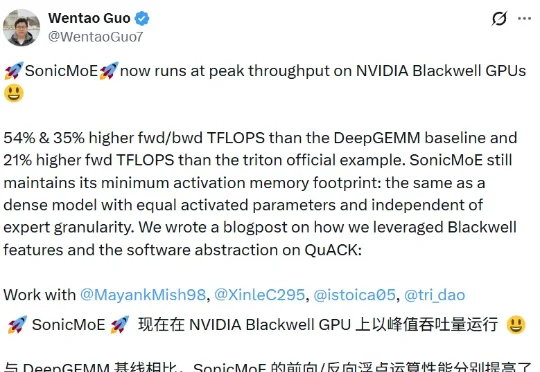
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。

几乎所有 Transformer 都在做一件反常的事:把大量注意力集中到少数几个特定 Token 上。这不是 bug,而是 Transformer 固有的「注意力汇聚」(Attention Sink)。首篇系统性综述,带你从利用、理解到消除,全面掌握这一核心现象。
前几天,一篇来自Kimi的论文「ATTENTION RESIDUALS」在 AI 圈引发了激烈讨论——马斯克罕见地发出评价:"Impressive work from Kimi"。同时,两位前Openai大佬也同样发出了高度评价,OpenAI 「推理模型之父」Jerry Tworek表示“深度学习2.0时代即将到来”。
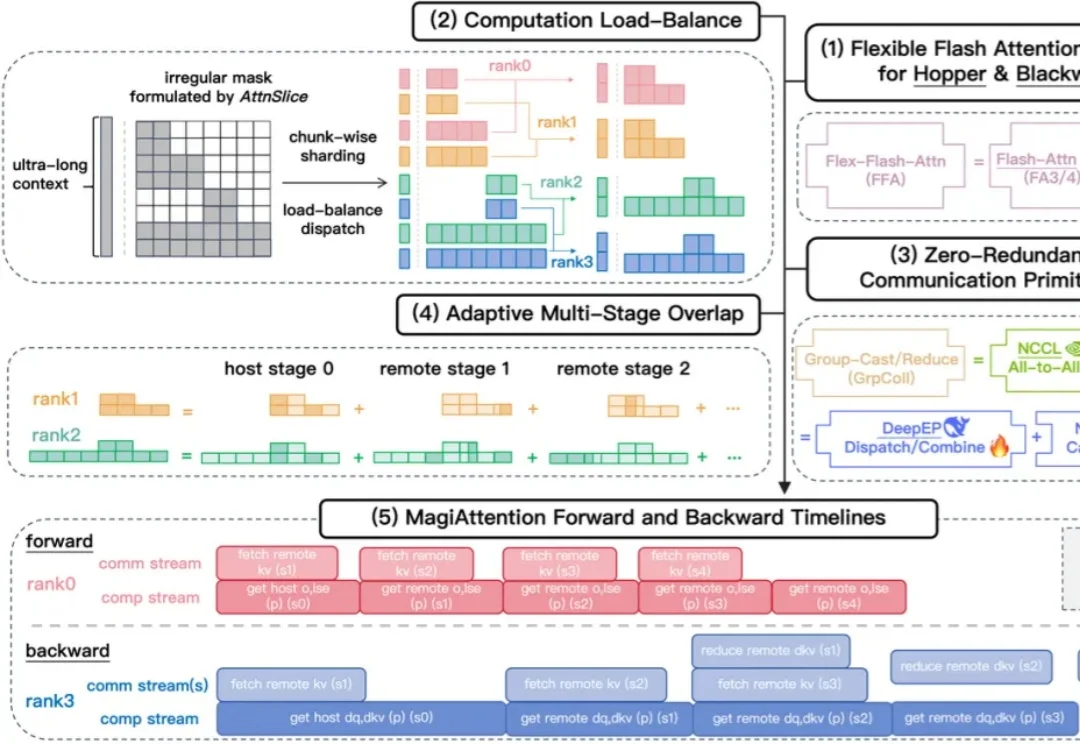
2025 年 4 月,Sand.ai 开源了 MagiAttention v1.0.0,定义了下一代分布式 Attention 的全新设计和系统框架。历经一年的深耕,今天 Sand.ai 正式发布:MagiAttention v1.1.0,以更成熟的原生算子组件,重新定义 Hopper 与 Blackwell 两代架构分布式 Attention 的性能上限。
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。

就在刚刚,Moonshot AI(月之暗面)发布了一项足以撼动 Transformer 底层的研究:《Attention Residuals》。海外科技大 V,谷歌高级AI产品经理 Shubham Saboo 直接开启了“高赞”模式:“他们触碰了那个十年没人敢碰的部分。”

近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!
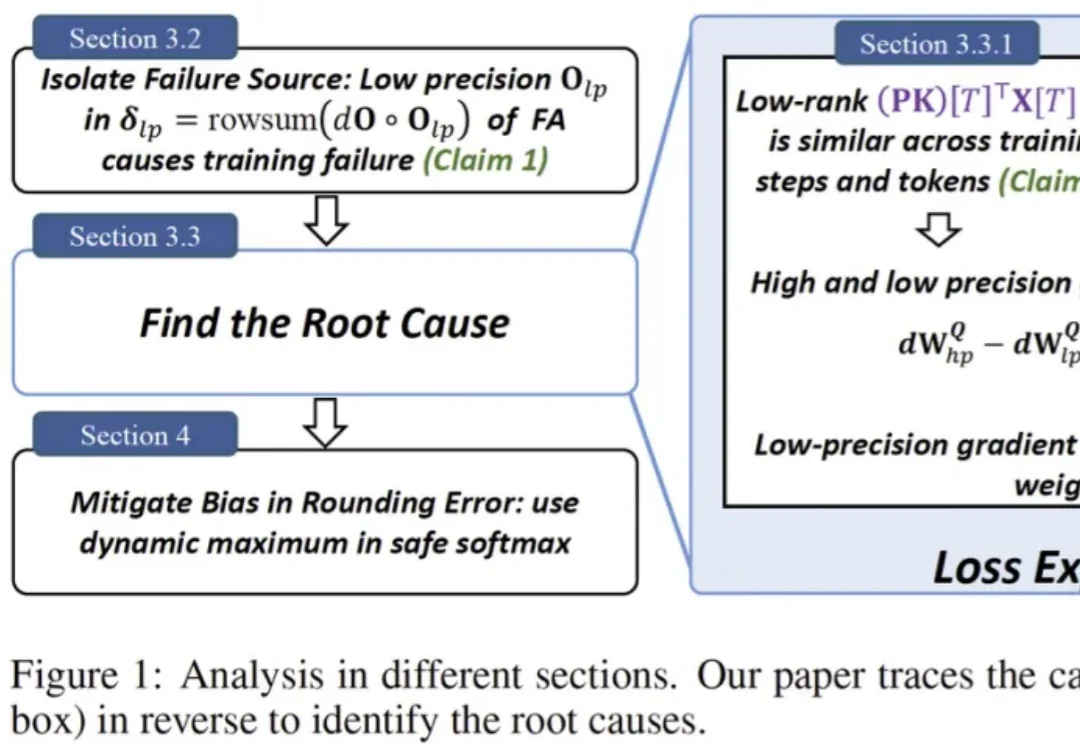
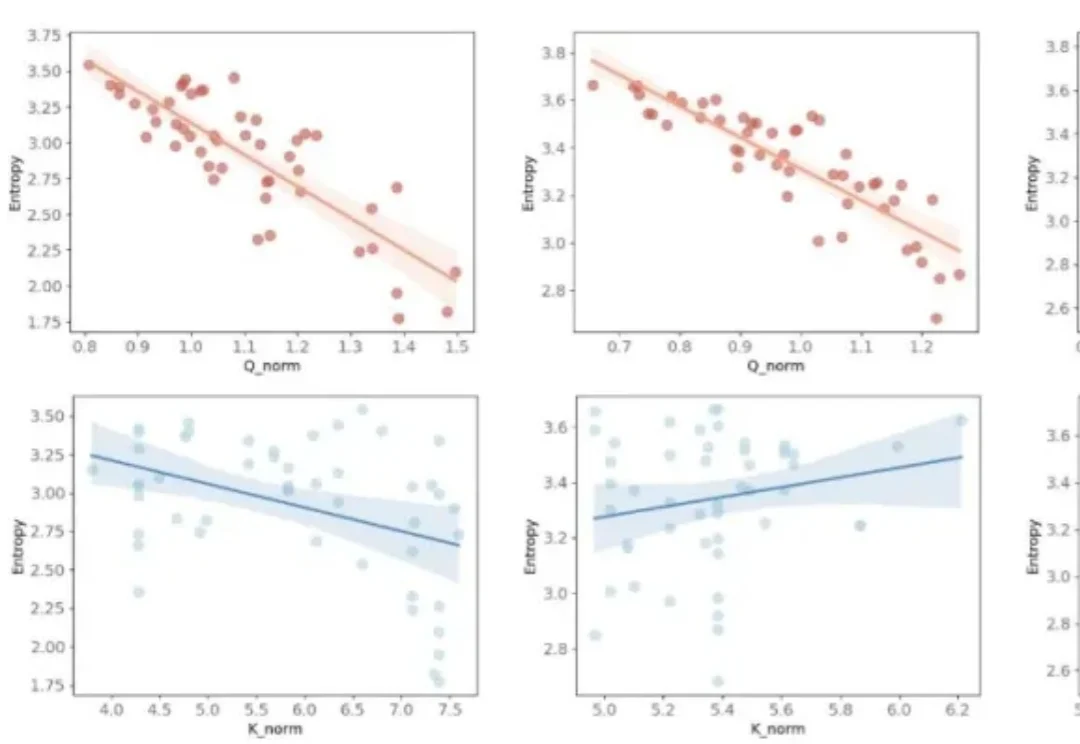
一句话总结:社区里困扰了多年的一个 “玄学” 现象终于被拆解清楚了:在 BF16 等低精度训练里,FlashAttention 不是随机出 bug,而是会在特定条件下触发有方向的数值偏置,借助注意力中涌现的相似低秩更新方向被持续放大,最终把权重谱范数和激活推到失控,导致 loss 突然爆炸。论文还给出一个几乎不改模型、只在 safe softmax 里做的极小修改,实测能显著稳定训练。